데이터 분석을 정확하게 하기 위해서는 우선 분석 목적에 맞는 데이터 세트를 만드는 것이 중요하다.
설문 조사를 진행하든 웹크롤링 등으로 데이터를 수집하든 긁어 모은 데이터 속에 불순물이 섞여 있는 일은 아주 흔하다.
Garbage in, Garbage out 이란 말이 있듯, 애초에 불량한 샘플이라면 아무리 화려하게 분석 능력을 펼쳐봤자 잘못된 결과물을 얻게된다.
따라서, 분석에 앞서 데이터를 목적에 맞게 준비하기 위한 데이터 전처리는 필수이며, 다음과 같이 데이터 정제 과정을 밟는다.
1. 데이터 오류 원인 탐색
- 결측값 확인 - 필요한 데이터 값이 누락됨
- 이상값 확인 - 특정 범위를 벗어난 튀는 값 (평균값 등에 영향을 미쳐 부정확한 해석으로 이끌 수 있음)
- 노이즈 확인 - 실제 입력되지 않았지만 입력되었다고 잘못 판단된
2. 데이터 정제 대상 선정
- 데이터 정제는 오류 데이터값을 정확한 데이터로 수정하거나 삭제하는 과정을 말한다
- 일단 기본적으로 모든 데이터를 대상으로 정제가 들어간다
- 특히 비정형, 반정형 데이터의 경우 데이터 품질이 막무가내기 때문에 더더욱 신경 써서 정제를 해줘야 한다
3. 데이터 정제 방법 결정
- 오류 데이터와 대상이 확인되면 해당 데이터값을 삭제하거나 대체값이나 예측값으로 수정할 수 있다
그럼, 오늘은 파이썬을 사용하여 결측값과 이상값을 찾고, 대체/예측값으로 수정하는 방법을 아래에 정리해 보겠다.
사용할 데이터는 머신러닝을 공부할 때 매우 자주 사용되는 "타이타닉" 데이터다.
타이타닉 데이터 셋은 생존에 유리한 조건을 가진 사람을 찾기 위한 분석/예측 연습으로 많이 사용되는 데이터다.
타이타닉에 탑승한 각 승객의 생존/사망 여부와 함께 성별, 나이, 티켓 지불 금액, 객실 등급 등의 정보가 제공된다.
이 데이터는 Kaggle 에서 다운받을 수 있다.
** 참고로, Kaggle에서 다양한 titanic 데이터 세트가 제공되고 있는데, 그 중 하나를 연습용으로 가져온거다.
< 파이썬으로 데이터 결측값 확인 >
1. 데이터 불러오기
우선, 아래의 스텝을 밟으며 데이터를 불러온다.
참고로, VS CODE 에서 ipynb 로 진행했다. 구글 코랩에서 진행해도 무관하다.
A) 판다스 라이브러리를 임포트 하기
B) 저장해둔 데이터 파일 불러오기
C) 데이터 파일 확인
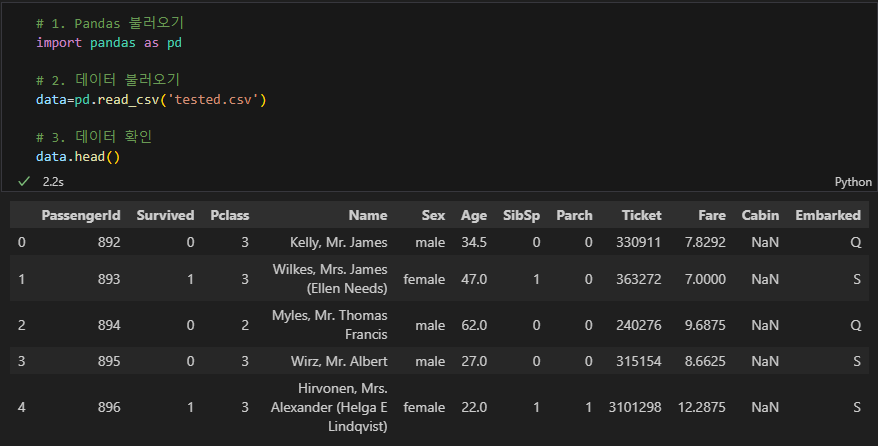
import pandas as pd # Pandas 불러오기
data=pd.read_csv('tested.csv') # 데이터 파일 불러오기
data.head() # 불러온 데이터 파일 확인
위와 같이 실행했을 때 아래처럼 데이터 파일이 문제 없이 열림을 확인했다.
2. 데이터 정보 확인
A) info()
결측치는 찾는 방법은 몇 가지 있는데 그 중 제일 선호 하고 간단한건 info() 메서드 사용인 것 같다.
info() 메서드를 사용하면 데이터프레임에 대한 다음의 정보를 한 번에 확인할 수 있다.
- 전체 행 개수
- 전체 열 개수
- 각 열의 null 개수
- 각 열의 dtype (int, object, float 등)
- 메모리 사용량
이 중 전체 데이터 행 개수와 각 열의 null 개수를 확인했을 때 개수가 맞지 않다면 해당 열에 결측값이 있다는 뜻이다.
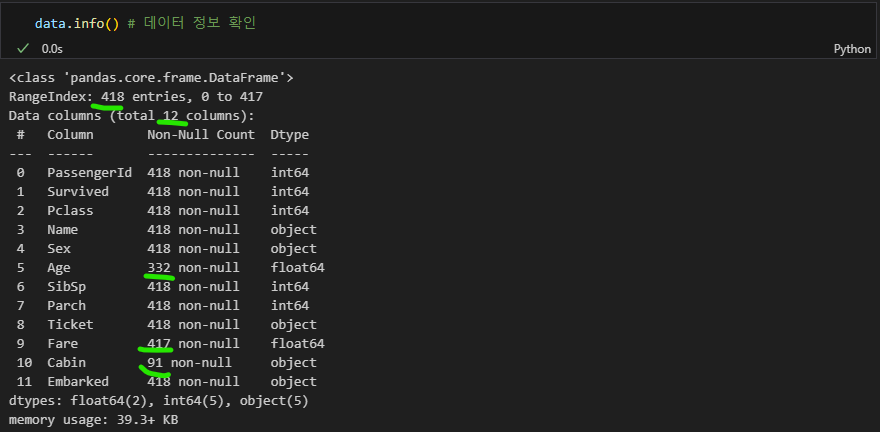
data.info() # 데이터 정보 확인
아래 결과값을 보면 Age, Fare, Cabin 열에 결측값이 있다는 것을 알 수 있다.
데이터의 다른 정보를 (총 열/행 개수, 데이터 타입 등) 확인하며 null 이 있는지 없는지 간단히 확인하기에 좋다.
대신, 총 null 데이터가 몇 개인지는 한 눈에 파악하기 어려울 수 있기 때문에 아래의 두 번째 방법을 이어서 사용해준다.
B) isna().sum()
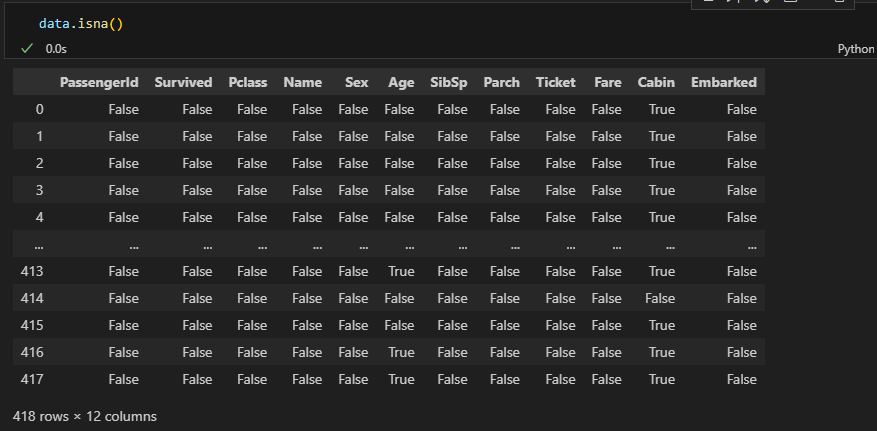
isna() 메서드는 각 행에 빈 값이 있는지를 확인하고 불리언 배열로 반환해준다.
따라서, isna() 만 사용하면 전체 열과 행에 대하여 True, False로 아래처럼 제시한다.
반면,
isna().sum() 로 두 메서드를 붙여서 사용한다면 각 열에 빈 값이 몇 개 있는지를 계산하여 제시해준다.
data.isna().sum() # 각 열의 총 null 값 개수 제시
info() 메서드 사용했을 때와 동일하게 Age, Fare, Cabin 에서 결측치가 각각 86, 1, 327 개 있음을 확인할 수 있다.
< 파이썬으로 대체/예측값으로 수정 >
결측치가 있을 경우 대체 값을 넣을 수도 있고 아예 해당 변수가 분석 목적과 맞지 않아 불필요하다면 제외시킬 수도 있다.
결측치 처리 방법을 결정하기 위해서는 분석 목적과 해당 변수의 결측값이 얼마나 많은지를 봐야한다.
타이타닉 데이터 셋을 통해 알아내고자 하는 바는 생존에 긍정적 영향을 미친 요인을 파악하는 것이다.
결측값이 있는 3개의 변수 Age, Fare, Cabin 중 Cabin의 경우 결측값의 비중이 매우 높다.
따라서, Cabin 은 분석에서 제외할 수도 있다.
이번 연습에서 Cabin 은 제외하고 Age 와 Fare 의 결측치 처리 방법만 다루기로 하겠다.
결측값 처리 방법은 크게 2가지로 나눌 수 있다:
1. 단순 대치법 (Single Imputation)
2. 다중 대치법 (Multiple imputation)
단순 대치법에도 몇 가지 방법이 있는데 오늘은 평균 대치법을 사용하여 결측치를 수정하도록 하겠다.
평균 대치법이란 주어진 데이터의 평균값으로 결측값을 대치하는 방법이다.
간단한 방식과, 조금 더 섬세한 터치를 가미한 방식으로 총 2가지를 아래에 정리하겠다.
1. 간단한 방식 - Age 의 평균값을 구해서 Age 열의 빈 값 일괄적으로 집어 넣기
다음의 과정을 밟는다:
A) Age 의 평균값 찾기
B) Age의 빈 값을 (A) 에서 찾은 평균값으로 넣어주기
A) Age 평균 찾기
age_mean=data['Age'].mean() # data 데이터프레임의 'Age' 열의 평균값 구하기
print(age_mean) # 평균값 확인
B) Age의 빈값 처리
데이터를 건드릴 때는 반드시 원본 데이터는 배려두고 복제한 데이터를 사용하시길!!
데이터프레임 복제는 copy() 메서드를 사용하면 된다.
data2=data.copy() # data 데이터프레임을 복제하여 data2로 새로 만들어줌
data2.head() # data2가 제대로 생성되었는지 확인
Age 의 null 값을 평균인 30.3 으로 대체하기 위해서는 fillna() 메서드를 사용할 수 있다.
data2=data2.fillna({'Age':age_mean}) # Age 열의 평균값을 담은 변수를 data2 의 Age 열의 빈값에 채워넣기
data2.isna().sum() # data2의 Age 열 빈값 처리가 되었는지 확인
2. 조금만 더 섬세하게 - 다른 변수를 고려하여 빈 값을 채우기
Age의 null값을 좀 더 섬세하게 대체해주기 위해 다른 데이터를 함께 확인하여 성별, title (Mrs, Mr, Miss), 등급 등에 따라 대체값을 다르게 설정하여 채워줄 수도 있다. 예를 들어, Title 이 Miss, Pclass=1 인 사람들의 평균 나이가 23이라면 이 케이스에 해당되는 빈 Age 값은 23으로 넣어주고, Title=Mr, Pclass=3 인 사람들의 평균 나이가 30이라면 이 케이스의 빈 Age 값은 30으로 넣어주는 식으로.
** 다만, 너무 섬세하고 복잡하게 만든다고 더 정확해지는 것은 아니다.
Age의 평균값으로 null값을 채우는 대신, Title 에 따라 평균 연령을 계산하여 해당 값으로 null 을 대체하는 방식을 아래에 설명하겠다.
A) 새롭게 결측값을 대체할거니 데이터프레임을 새로 복제해준다.
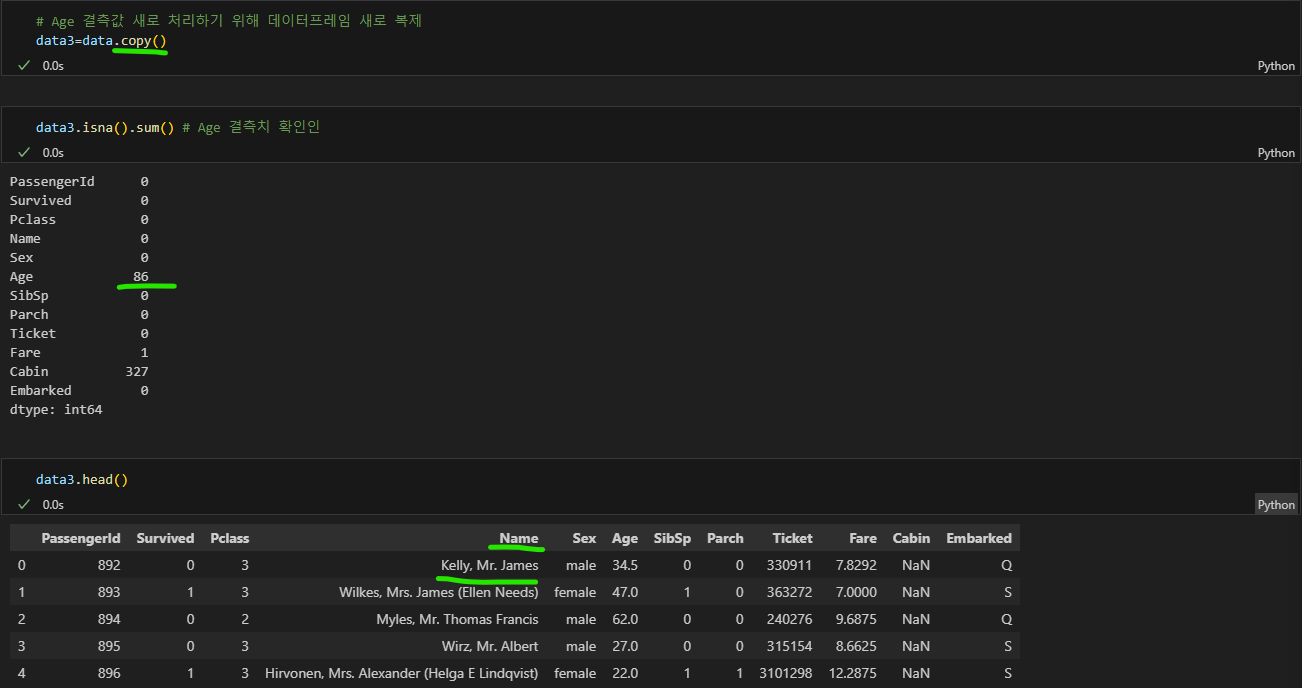
data3=data.copy() # Age 결측값 처리를 새로하기 위해 data 데이터프레임을 새로 복제
data3.isna().sum() # Age 결측값 확인
data3.head() # Name 구분을 위해 구조 확인
B) Title 추출
Name 열의 값을 보면 Surname, Title. Given name 의 형식으로 문자열이 들어가 있다.
성은 쉼표로 ( , ), 타이틀은 온점으로( . ) 구분되어 있다.
구분자가 다르게 들어가 있기 때문에 replace() 메서드와 split() 메서드를 사용하여 문자열을 나누도록 하겠다.
data3[['Surname','Title','Given_name']]=data3['Name'].str.replace('.',',').str.split(',', expand=True)
data3.head()
# data3에 Surname, Title, given_name 으로 열을 새로 추가하고,
# 새로 추가된 열에는 각각 다음의 데이터가 입력되는데
# data3의 Name 열의 온점( . ) 표기는 쉼표( , )로 바꾸고
# 문자열의 쉼표( , )를 기준으로 잘라서
# 새로 생성한 각 열에 집어 넣으라는 뜻
# data3.head() ==> data3의 처음 5개 열까지 보여주기

C) Title 열 유니크 값 확인
일단 Title 열에 어떤 값이 있는지를 먼저 확인해보자.
data3['Title'].unique() # Title 열의 모든 값을 중복없이 리스트해줌
Mr, Mrs, Miss, Master, Ms, Col, Rev, Dr 로 총 7개의 타이틀이 있다.
D) Title 앞 공백 제거
타이틀 값 앞에 공백이 있는데, 데이터프레임에서 왼쪽 공백을 제거하기 위해서는 str.lstrip()을 쓰면 된다
data3['Title']=data3['Title'].str.lstrip() # Title 열의 값 앞단의 공백 제거 & 저장
data3['Title'].unique() # Title 열의 유니크 값 확인하여 공백 제거 체크
E) Title 열의 타이틀 별 평균 연령 구하기
각 타이틀 별 연령 mean 값은 groupby() 와 mean() 을 사용하여 구할 수 있다
title_age_mean=data3.groupby('Title')['Age'].mean() # Title 별로 Age 평균값 구하기
title_age_mean # 타이틀 별 평균 연령 미리보기
각 7개의 타이틀 별로 Age 평균값이 구해졌다.
Ms 에 NaN 가 떠 있는게 보인다.
평균을 구할 때 null 값이 있다면 해당 부분은 제외하고 평균이 구해진다.
따라서, Ms 에 NaN 이 떴다는 것은 Ms 에 해당되는 Age 열이 모두 비어있다는 뜻이된다.
F) Title 열 Age 열의 null 값 확인
하여, Title 별로 Age 값이 있는 케이스와 없는 케이스의 수를 한 번 확인해보겠다.
먼저, 값이 있는 케이스부터 확인하자.
data3.groupby('Title')['Age'].count() # 타이틀 별 Age 열에 데이터가 몇 개 있는지 확인
예상한 것처럼 Ms 의 Age 열에는 데이터가 하나도 없다.
그렇다면 Ms 의 빈 Age 값을 어떻게 채워줄지 고민이 된다.
하여, Ms의 Age null 값을 확인해 몇 개 비어 있는지 부터 확인해보자.
data3.groupby('Title')['Age'].apply(lambda x:x.isna().sum())
Ms 는 고작 1개만 데이터가 없다.
Ms 는 결혼여부와 상관없이 여성을 가리키는 타이틀이다. Mrs 와 Miss 중 어디에 더 적절할지 확인을 위해 Title=Ms 인 샘플의 다른 데이터를 확인해보도록 하겠다.
data3[data3['Title']=='Ms'] # data3의 'Title' 열의 데이터가 'Ms' 인 케이스를 제시
Title=Ms 에 해당되는 샘플의 데이터를 보면 결혼/미혼 상태를 알기가 어렵다.
SibSp 변수는 Sibling/Spouse 로 형제 혹은 연인/남편 수를 담고 있다.
Parch 변수는 Parents/Children 으로 부모 혹은 아이의 수다.
PClass 는 티켓 등급으로 1= 일등급, 2=2등급, 3=3등급을 의미한다.
Fare 는 타이타닉에 타기 위해 지불한 금액이다.
** 변수에 대한 설명은 Kaggle Titanic Dataset 의 데이터 정보 부분에서 확인할 수 있다.
주어진 정보로는 이 샘플이 Miss 일지 Mrs 일지 알기 어렵다.
하지만 시대적 배경을 고려했을 때 미혼의 여성이 혼자 타이타닉을 타기보다는 연령대가 있는 여성이 혼자 타는 게 좀 더 설득력 있을 것 같다.
따라서, Title=Ms 를 Title=Mrs 로 수정하고, Age 값도 Mrs의 평균 연령으로 넣도록 하겠다.
그 외 Master, Miss, Mr, Mrs 는 각각 타이틀의 평균값으로 대체하겠다.
G) Ms => Mrs 로 데이터 수정
data3['Title'].replace({'Ms':'Mrs}, inplacae=True) # Title열에서 Ms => Mrs 로 수정
H) 각 타이틀의 평균 연령에 맞춰 Age 열 채우기
우선, 타이틀별 평균 연령 값을 담을 변수를 만들어준다
title_age_mean=data3.groupby('Title')['Age'].mean() # title_age_mean 변수에 타이틀 별 평균연령 값 담기
title_age_mean # 값 확인
이제 title_age_mean 으로 data3 데이터프레임의 Age 열에 타이틀에 맞게 들어가도록 하겠다.
data3['Age']=data3.apply(lambda row: title_age_mean[row['Title']] if pd.isna(row['Age']) else row['Age'], axis=1)
data3.head()
# data3['Age'] 열에 다음과 같이 적용하는데:
# Age 열에 빈 값이 있을 경우 title_age_mean 변수에서 동일한 Title을 가진 age 값으로 넣고
# 그렇지 않다면 (Age 열에 값이 있다면) 기존 값을 유지
마지막으로, Age의 결측값이 다 채워졌는지 확인을 해보면, 아래와 같이 총 null 개수 0임을 확인할 수 있다.

Fare 도 Age 처럼 유사하게 처리해주면 되고, Cabin 의 경우 불필요한 변수 같으니 추후 데이터 세트에서 제외시키면 된다.
'파이썬 - 분석 라이브러리' 카테고리의 다른 글
| [파이썬] 데이터 이상치 확인 | Matplotlib 박스플롯 시각화, subplots (0) | 2025.02.15 |
|---|---|
| [파이썬] Open() 함수, UnicodeDecodeError, chardet, chardet.detect() (0) | 2024.08.21 |
| [파이썬] 시리즈/데이터프레임 인덱싱 - iloc, loc (0) | 2024.06.12 |
| [파이썬] 데이터프레임 인덱스 수정 - set_index, reset_index, reindex, drop, index.name (0) | 2024.06.11 |
| [파이썬] 데이터프레임 정보 확인 - info, describe, columns, count, unique, dtype, head (0) | 2024.06.10 |



